








在机器学习或者深度学习领域,我们常常会用到混淆矩阵,以及与之相关的一些评价指标,今天就稍微总结一下什么是混淆矩阵以及里面的一些评价指标及其相关含义。
混淆矩阵
混淆矩阵又叫做误差矩阵,是表示精度评价的一种标准格式,常常用n行n列的矩阵来表示,而通常在二分类的任务中,我们常常用下面的矩阵来表示混淆矩阵。
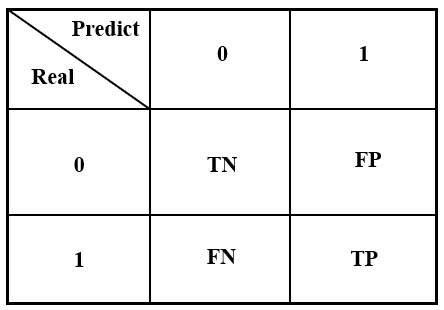
上图是一个二分类混淆矩阵的标准形式,在二分类中0我们称之为负类,也就是negative,而1我们称之为正类,也就是positive。上图中我们的解释一般如下:
- 实际是负类,预测的也是负类,那么就是TN,也就是真负,True Negative。
- 实际是正类,预测的是负类,那么就是FN,也就是假负,False Negative。
- 实际是负类,预测的是正类,那么就是FP,也就是假正,False Positive。
- 实际是正类,预测的是正类,那么就是TP,也就是真正,True Positive。
基于混淆矩阵的相关评价指标
上面说到过,混淆矩阵是一种精度评价的标准格式,光只有个矩阵,我们没办法量化出相关的指标,也没办法做出相应的判断,于是就有了基于混淆矩阵的一系列的评价指标,相关计算公式我们也会在下面给出。
- Precision:注意,这里是精确率,不是准确率,而精确率又叫查准率,只关注正的样本。也就是在预测为正例中,有多少是预测对的。
- Recall:这里指的是召回率,又叫查全率,关注的是正的样本,但是关注的是在原本数据集的正样本中,有多少正样本被识别出来。
- Accuracy:这就是我们通常说的准确率了,也就是预测是对的(不论正负),占所有数据的比例。
- F1 Score:通常我们叫做F1度量或者F1分数,它是由精确率和召回率的调和平均数。下文会解释为什么用调和平均数。
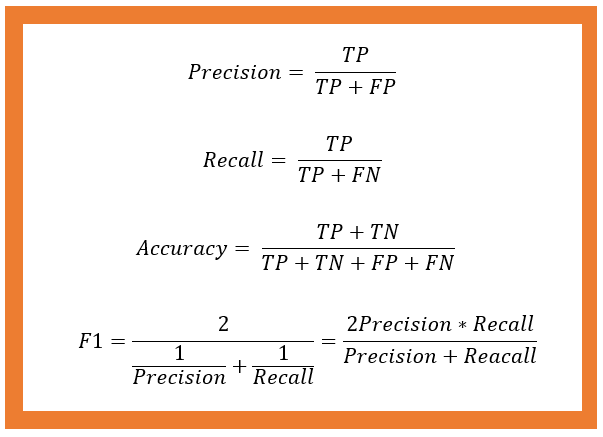
相信大家看到前面三个公式就能够理解各自的含义了,精确率表示查准率,召回率表示查全率,就是一个查全,一个查准,而准确率则是衡量整体预测对,这样的指标。而实际上,我们不仅要查全,而且要查准。

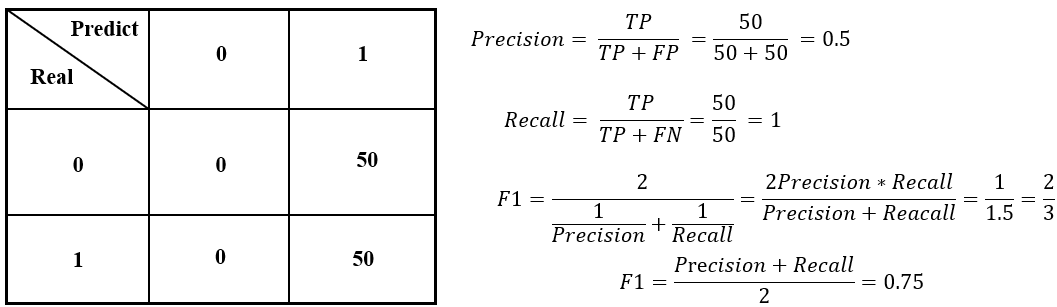
而对于F1度量为什么使用的是调和平均数,而不是算术平均数呢?这里举一个实际的例子吧,如下图所示。假设正样本有50个,负样本有50个,全部预测为正样本,那么精确率为0.5,召回率为1。使用调和平均数的F1度量为三分之二,也约等于0.67。而使用算术平均得到的结果为0.75,相当于对于这两个指标都同等看待,但是我们知道召回率为1的时候,我们更看重精确率,所以对于精确率的权重要大一些,召回率的权重要少一些,所以,用调和平均的结果要更合理一些。这就是为什么使用调和平均来计算F1度量,而不使用算术平均了。
Q.E.D.

